MongoDB
介绍
MongoDB:适用海量存储,基于文档数据库,C++编写,开源产品,遵循GNU AGPL,支持OSX,Linux,Windows,Solaris。
MongoDB:适用于web站点,cacheing,高大数据量,高扩展场景,事物要求性不高的场景。
MongoDB面向集合的数据库 :
数据库:但数据库无须创建
集合:无须事先定义,一个文档相当于mysql中的一行,集合相当于多个文档组成的,mongodb中集合是基本的操作单位
特点:
文档存储:利用json组织数据
性能好:c++,多索引支持,不支持事物(支持原子事务),基于内存(延迟写)
支持复制:类似mysql主从复制replication(废弃) 副本集复制auto-sharding
自动分片机制
支持map/reduce.可以实现并行查询处理
分布式文件系统
支持基于位置索引(空间)
商业支持,很多公司使用mongodb
MongoDB可以文档嵌套,KEY/VALUE存储,存储格式JSON,实例
1 | { |
Mongodb架构
1 | C/S架构: |
MongoDB安装
配置yum源码
1 | vi /etc/yum.repos.d/mongodb.repo |
查询MongoDB软件包
1 | yum search mongod* |
安装mongodb
1 | yum install mongodb |
添加权限
1 | useradd mongod |
启动mongodb
1 | server mongod start |
如果想访问mongod监控端口需要启动端口27017,28017(需要开启httpinterface)
访问 http://192.168.2.21:27017 监控端口,显示mongodb信息
Mongod客户端
mongo [option][db address] [file name]
mongo 默认连接127.0.0.1:27017 默认没有用户密码认证
例子:
1 | mongo 192.168.2.21 |
MongoDB常用命令
1 | mongodb常用的命令 |
MongoDB配置文件
mongodb配置文件在/etc/mongod.conf下
1 | more /etc/mongod.conf |
MongoDB 使用
MongoDB基本使用
1 | mongo 192.168.2.21 |
MySQL和MongoDB语法比较
INSERT插入
1 | mysql>insert into studycoll(name, age,status) value ('zhuxy','19','A') |
SORT排序
1 | mysql>select * from studycoll where age > 18 |
SELECT查询
1 | mysql>select name, gender from studycoll where age > 18 limit 5 |
UPDATE更新
1 | mysql>update studycoll set status='A' WHERE age > 18 |
DELETE删除
1 | mysql>delete from studycoll where status='D' |
AND方法
1 | mysql>select * from studycoll age > 70 and age < 75 |
关系型数据库和MongoD
| RDBMS | Mongo |
|---|---|
| table.view | collection |
| row | Json Document |
| index | index |
| join | embedded |
| partition | shard |
| partition key(分区键) | shard key(分片键) |
MongoDB高级操作
批量插入
1 | mongodb>for(i=1;i<=100;i++) db.studycoll.insert({name:"User"+i,age:i,gender:"M",books:['linux','python']}) |
find
mongodb查询操作支持挑选机制,comparison,logical,element,javascript等几类
comparison比较运算符
1 | gt 大于{filed:{$gt:value}} |
logical逻辑运算符
1 | or 或{$or:[{<expression1>},{<expression2>}]} |
element元素查询
1 | exists #根据指定字段存在性挑选文档,语法格式{filed:{$exists:<boolean>}},指定<boolean>的值为true,则返回存在指定字段的文档,false则返回不存在指定字段的文档 |
exists
用法查询有address字段的文档
1 | mongodb>db.studycoll.find({address:{$exists:true}}) |
update
update参数使用格式独特,其仅能包含使用update专有操作符来构建表示式,其中大致包含‘filed’,’array’,’bitwise’
filed类常用操作
1 | inc #增大指定字段,格式{field:value},{$inc:{field1:amount}},其中{field"value}用于指定挑选标准,{$inc:{filed:amunt}}指定要提升其字段及提升大小amount |
总结
1 | 1,mongodb常用方法CRUD |
索引
假设从一百万条数据,在关系型数据库中,找到一个数值改怎么办?难道全表扫描?
推荐读:“关系型数据库索引设计与优化”
这本书介绍如何设计索引:(索引也会带来坏处),数据库使用索引,保存的索引文件占用资源,如果数据被修改,索引也应该需要修改,降低写入性能,有利必有弊。
需要根据现有的环境来确定是否使用索引:
如果数据量小,无需索引,如果创建索引反而变慢
如果数据量多,需要根据查询的条件来决定是否创建 简单索引 或者 组合索引
如果数据量海量,创建索引没有意义
索引是什么
在关系型数据库中,索引是一种单独的,物理的对数据库表中一列或多列的值进行排序的一种存储结构,是某个表中一列或者若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单
作用相当于图书目录,可根据目录中的页码快速找到所需内容
索引优点
1,减少服务器需要扫描的数据量
2,索引可以帮助服务器避免排序或者使用临时表
3,可以将随机i/o转化成顺序i/o
索引级别
1星:索引如果能将相关的记录放置在一起,降低I/O,入门级别
2星:索引中数据的存储顺序与查找标准中顺序一致。
3星:如果索引中保护查询中所需要的全部数据,(覆盖索引)。
索引类别:
顺序索引
散列索引:将索引映射至散列桶上,映射是通过散列函数进行的
评估索引标准:
访问类型:范围查找用顺序索引,等值查找用散列
访问时长
插入时长
删除时长
空间开销
顺序索引
聚集索引。如果某记录文件中的记录顺序是按照对应的搜索码指定的顺序排序,聚集索引也叫主索引。不需要二次i/o,找到键就找到行了。
非聚集索引。搜索码中的指定次序与记录文件中的记录次序不一致,叫非聚集索引,需要找到键,在寻找指针指定的行。
有聚集索引的数据文件,也叫做索引的顺序文件。
根据索引中是否为每个记录相应的创建索引项:稠密索引 和 稀疏索引
多级索引:
一级索引指向二级索引,二级索引指向行
辅助索引必须是稠密索引
B+树索引:
Balance Tree:平衡树索引
MYISAM是非聚集索引
InnoDB是聚集索引(数据文件和索引文件在一个文件中)
顺序索引的特性:
全值匹配:Name=”user12”
匹配最左前缀:Name like “User1%”, 无效:Name LIKE “%User1%”
匹配列前缀:Name like “User1%”, 无效:Name LIKE “%User1%”
匹配范围值:
精确匹配某一列并范围匹配另一列
只访问索引的查询:覆盖查询
组合索引特性:
如果索引是这样的(Name,Age), 那么Age > 80无效,最左查找的;
如果Age>80 and Name = “user12”有效
散列索引:
不适合范围查询,适合精确值查询
散列函数
分布要随机
分布要均匀
适用场景:
精确匹配: =,IN(),<=>
MySQL索引
只有MyISAM存储引擎支持,可以借助sphinx,lucense实现
空间索引,必须使用空间索引函数获取相应的查询结果,MyISAM支持
主键(值不能相同,也不能为空)
唯一键(值不能相同,可以为空)
mysql创建索引
1 | 创建索引:CREATE INDEX index_name ON table (col1,...) |
MongoDB支持的索引
简单索引
组合索引
多键索引
空间索引
全文索引
哈希索引
MongoDB索引操作
1 | db.studycoll.find({name:"User49"}).explain() |
MongoDB复制
mongodb复制架构
早期mongodb使用类似mysql复制功能,但是发现主不能故障转移
Replica Set复制集(副本集),类似mysql复制功能,可实现故障转移功能
mongodb官方不建议使用主从方式
Replication Options
副本集相关选项:
replSet #指定副本集名称
oplogsize #操作日志大小,在64位系统下,默认是可用磁盘空间的5%,如果mongodb初始化后,后期修改oplog是不生效的
fastsync #快速同步,类似后台复制
replIndexPrefetch #mongodb2.2才能实现,指定副本集的索引预取,可以让复制过程更为高效
replIndexPrefetch {none | _id_only | all} non不预取任何索引,_id_only预取id索引,all预取所有索引副本集架构时间要同步,replset名称一致,确保mongodb能交互
部署配置
1 | 环境: |
Mongod Sharding
mongod副本集 不能降低I/O的请求,只是把数据复制一份到另外一台机器,考虑到后期高并发高吞吐量场景或者数据大于物理磁盘的时候,就需要使用sharding分片
shareding只是将大数据切割成小数据分散至其他机器上。降低i/o压力
Sharding目的:
数据系统巨大和高吞吐量高
高并发的查询会耗尽cpu的资源
sharding可以降低单台服务器的I/O压力
Sharding架构
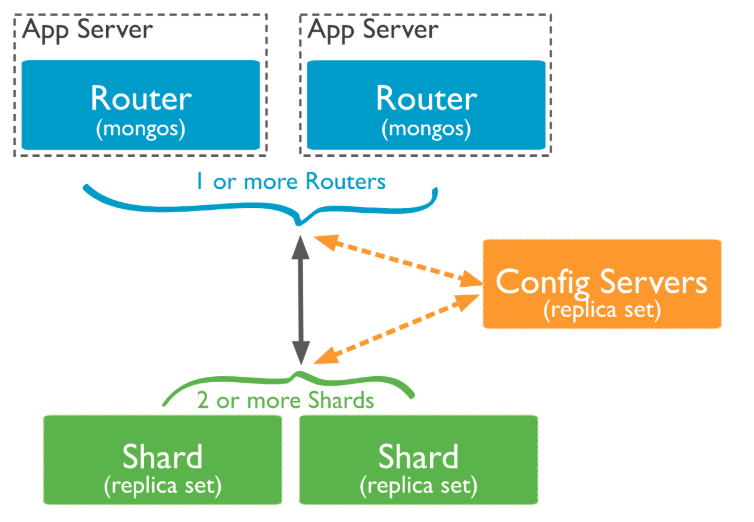
router 跟config server通讯(router可以有一个,可以有多个)
config server 存储元数据(分区键),在生产环节中建议使用三个config server,一个单点故障,两个不方便选举
share 数据
注意事项:
做sharding对写操作最好做到分散,降低写压力, 对读操作最好不要做到分散,才能降低i/o压力
所以最好做到,写尽可能离散,读尽可能不离散。选择一个合理的分区键(通常使用组合键进行切割)。
环境部署
1 | 环境说明: |
总结
1 | 重复索引: |

